
Currently, GPUs are the most popular platforms for realizing deep neural networks (DNNs). However, due to their high power consumption, they are usually not suitable for edge computing, with the exception of systems like NVIDIA Jetson. Various AI hardware has been developed, many tailored specifically for edge applications. Multiple articles have broadly classified AI hardware, providing a comprehensive overview of current trends in AI accelerators.
This article offers an extensive introduction to edge AI processors and Processing-in-Memory (PIM) processors within the industry. This includes processors already released, announced processors, and those disclosed in research institutes such as ISSCC and VLSI conferences. Data presented here is collected from open-source platforms, including scientific articles, tech news portals, and company websites. Exact figures may differ from this report. For those interested in a specific processor, verifying performance data with the provider is advisable.
The article is divided into four sections: (i) descriptions of data-flow processors; (ii) neuromorphic processors; (iii) PIM processors; and (iv) industrial research on processors.
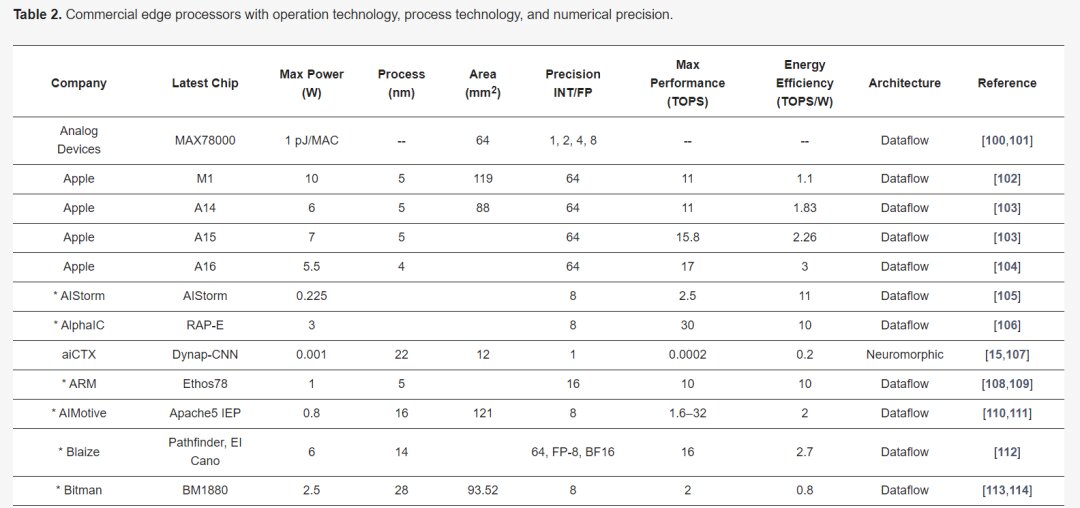
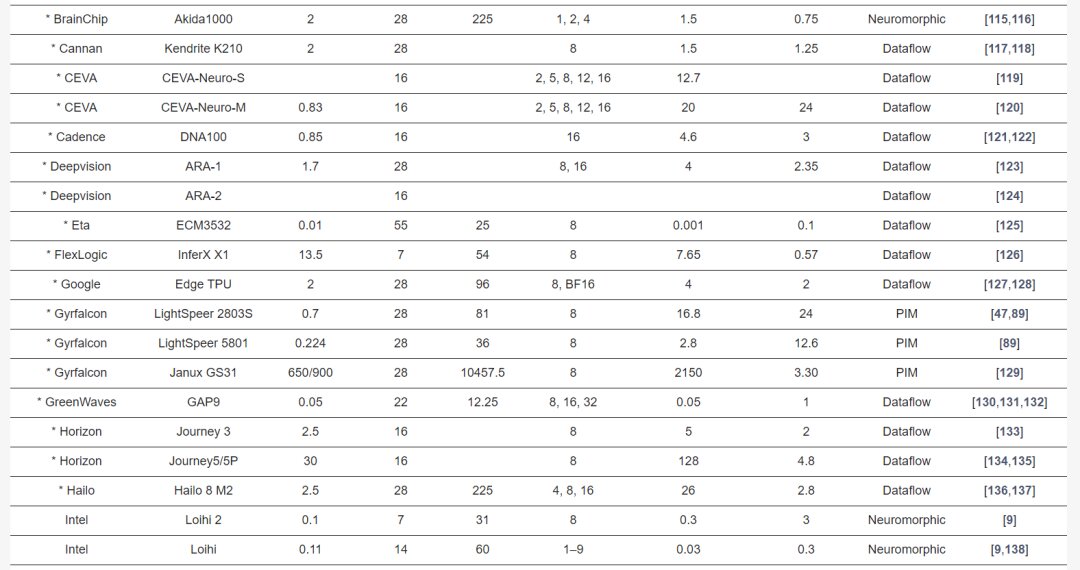
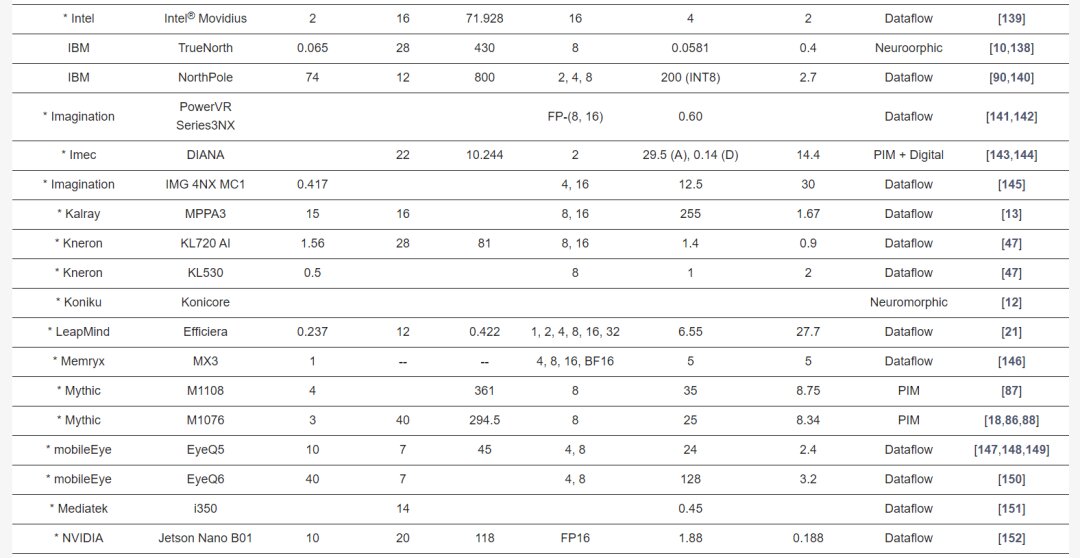
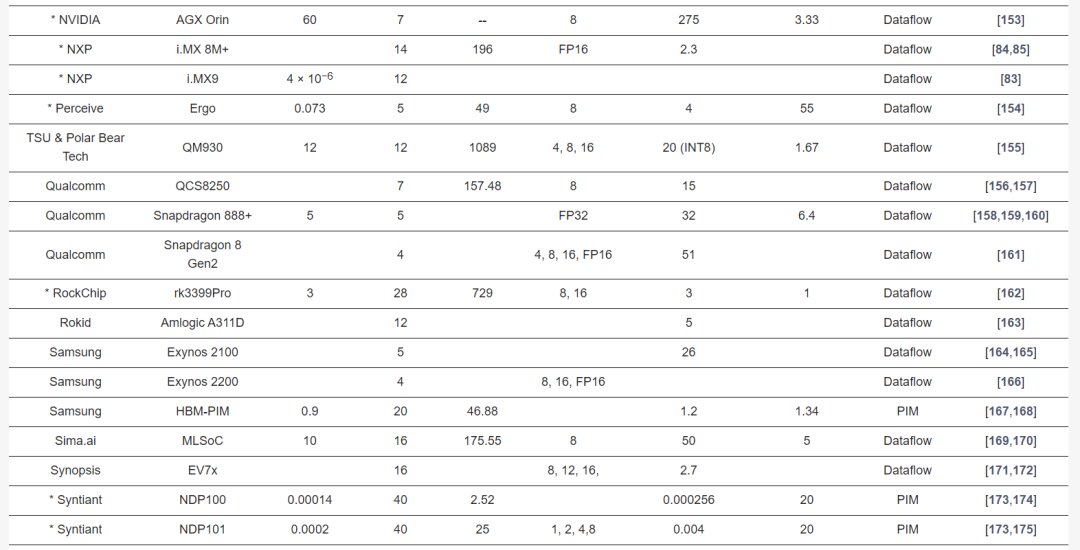
Overview of Commercial Edge-AI and PIM-AI Processors
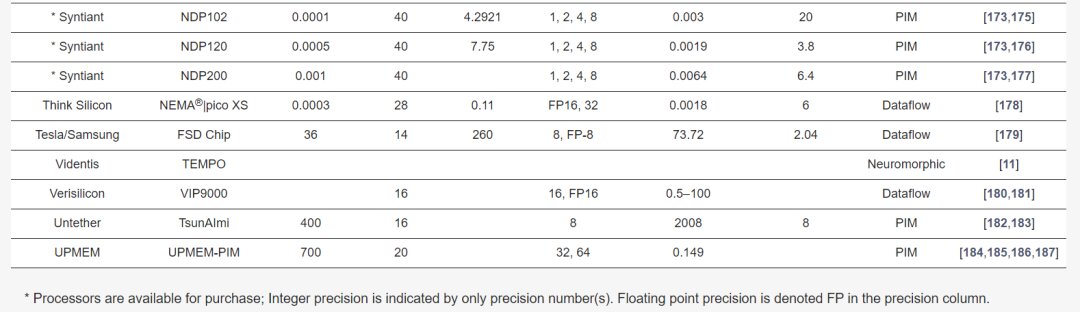
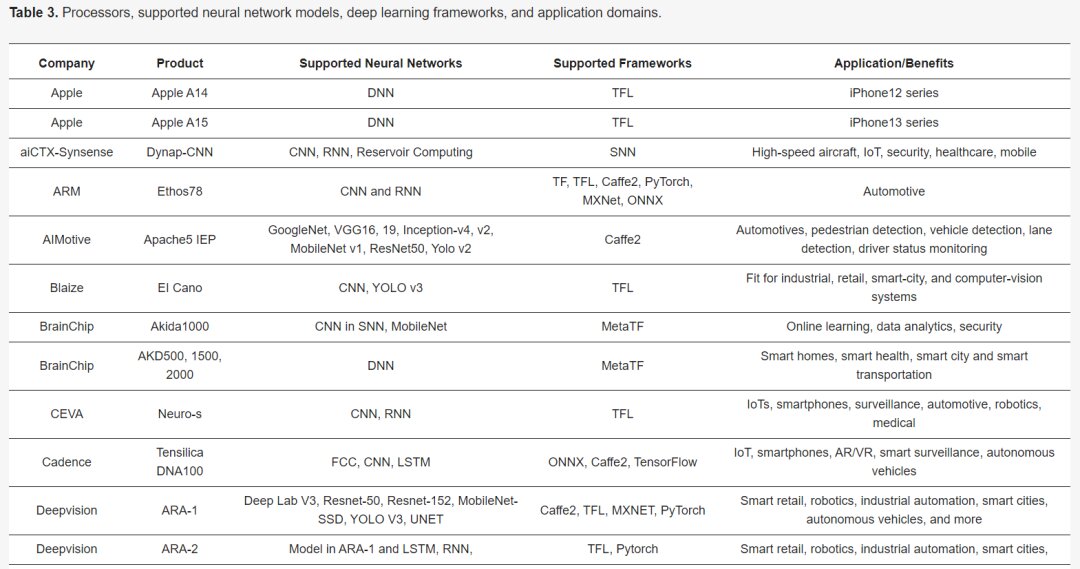
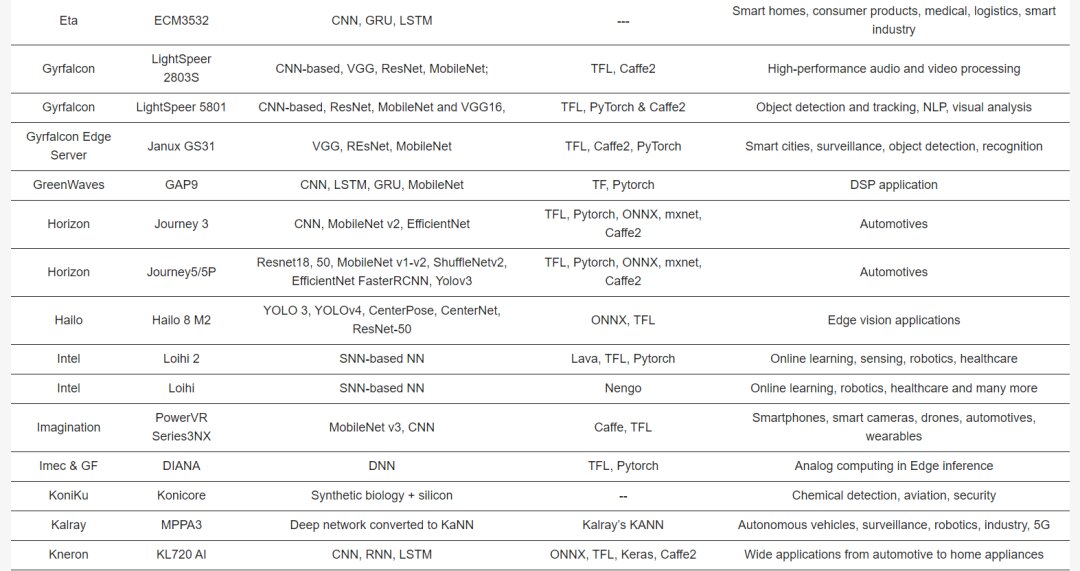
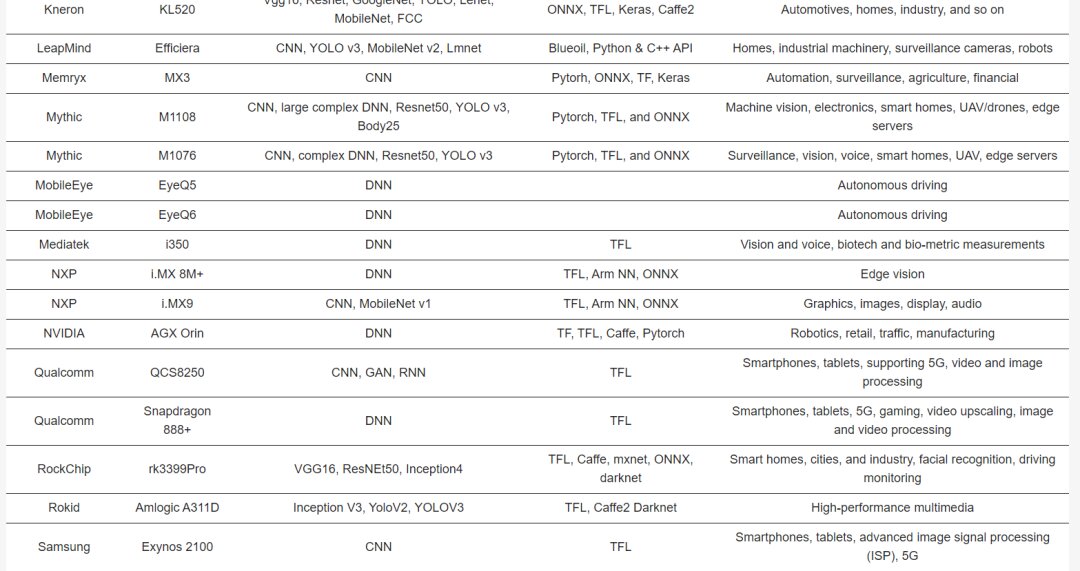
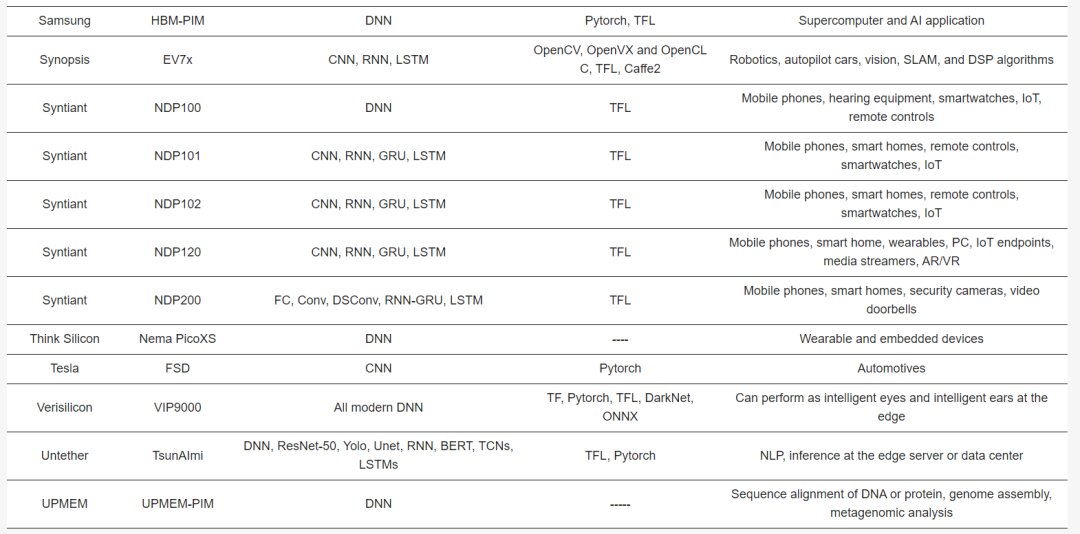
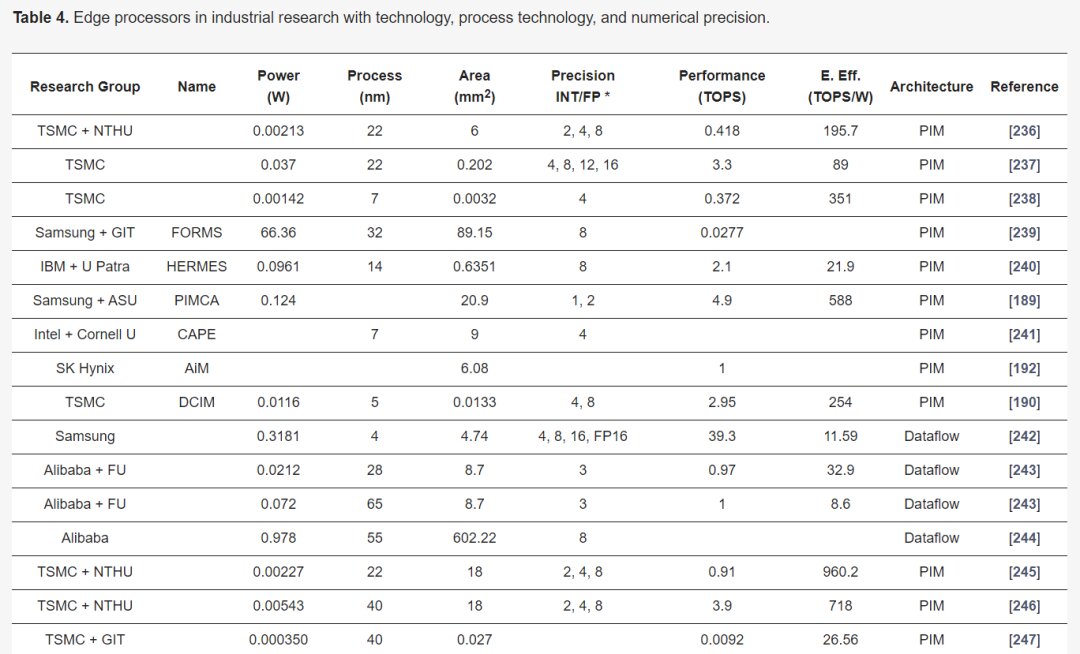
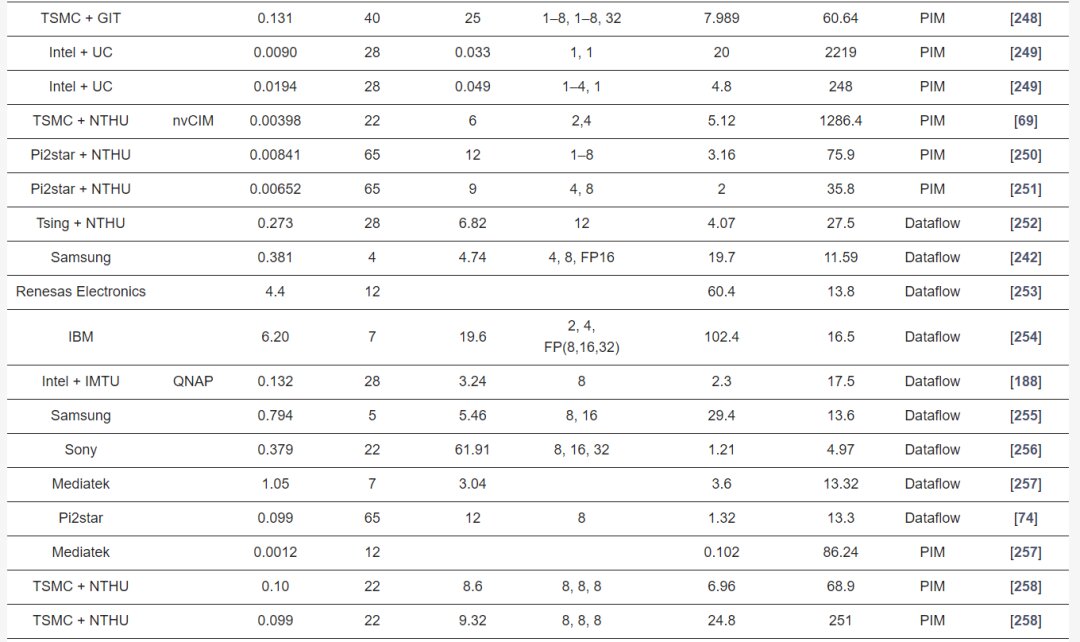
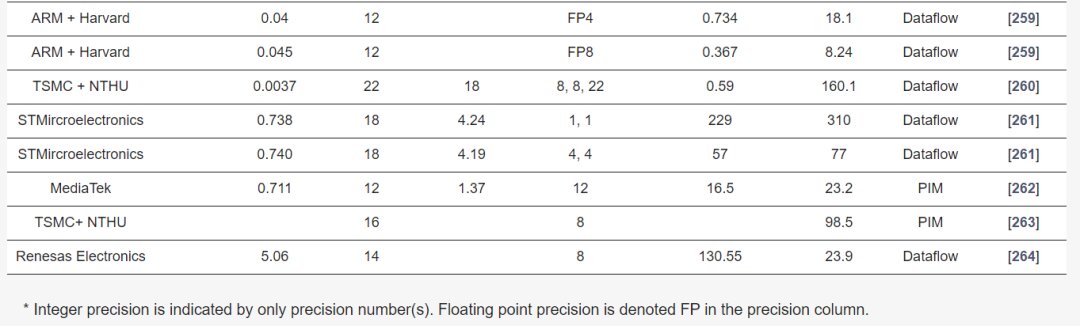
Table 2 describes the major hardware characteristics of commercial edge-AI and PIM-AI processors, while Table 3 lists the key features of processors from industrial research. Table 4 outlines the critical software/application features of processors in Table 2.
Data-Flow Edge Processors
Analog Devices Inc. has developed an affordable mixed-signal CNN accelerator, the MAX78000. This accelerator comprises a Cortex-M4 processor, a 32-bit RISC-V processor with an FPU, and a CPU for system control with a DNN accelerator. Weights are stored on-chip within a 442KB SRAM, supporting 1-bit, 2-bit, 4-bit, and 8-bit weights. The CNN engine has 64 parallel processors and 512KB of data memory, with each processor containing a pooling unit and a convolution unit with dedicated memory. The processor consumes 1pJ per operation. However, performance data in TOPS and power consumption (W) are not yet available. The chip size is 64 square millimeters and supports PyTorch and TensorFlow toolsets for developing various DNN models. Its target applications include object detection, classification, facial recognition, time series data processing, and noise reduction.
Apple has released the Bionic SoC A16 with an NPU unit for the iPhone 14, boosting performance by about 20% compared to the A15 at the same power consumption. It includes a 6-core ARM8.6a CPU, a 16-core NPU, and an 8-core GPU. The Apple M2 processor, released in 2022 and optimized for MacBooks and iPads, features a 10-core GPU and a 16-core NPU. The M1 yields 11 TOPS, consuming 10W. The M2 enhances CPU and GPU performance by 18% and 35%, respectively.
ARM recently introduced the Ethos-N78 for automotive applications, an upgrade from the Ethos-N77, supporting INT8 and INT16 precision. The Ethos-N78 shows over a twofold performance improvement due to a novel data compression method enhancing bandwidth and energy efficiency.
Blaze released the Pathfinder P1600 El Cano AI inference processor with 16 Graphic Stream Processors (GSP), delivering 16 TOPS at peak performance. It operates dual Cortex-A53 processors running at 1GHz for the operating system.
AIMotive’s Apache5 edge inference processor supports various deep neural network models, featuring the aiWare3p NPU with an efficiency of 2TOPS/W, supporting INT8 MAC and INT32 internal precision, targeting autonomous vehicles.
CEVA has launched the Neupro-S edge AI processor for computer vision applications. Neupro includes two independent cores: a DSP-based VPU and the Neupro Engine handling most computations at INT8 or INT16 precision, delivering up to 12.5 TOPS per single processor and scalable to 100 TOPS in multi-core clusters.
Cadence unveiled the Tensilica DNA 100 SoC for edge AI accelerators, offering 8 GOPS to 32 TOPS of AI performance, targeting applications like IoT, smart sensors, vision, and voice apps.
DeepVision’s updated edge inference coprocessor, ARA-1, for autonomous vehicles and smart industries, includes eight compute engines and achieves 4 TOPS at 1.7-2.3W. The upcoming ARA-2, supporting additional neural networks, is set to launch later in 2022.
Horizon announced the Journey 5/5P automotive AI inference processor, an upgrade from Journey 3, with a forthcoming production set for 2022. It offers 128 TOPS performance at 30W, yielding 4.3 TOPS/W energy efficiency.
Hailo’s Hailo-8 M-2 SoC for diverse edge applications supports INT8 and INT16 precision, delivering 26 TOPS at 2.5 W and functioning as both standalone and coprocessor units.
Google introduced the Coral Edge TPU, occupying only 29% of the size of the original TPU for edge applications, enhancing energy efficiency in DNN computations. It supports INT8 precision, delivering 4 TOPS at 2W.
Google’s Tensor processor, paired with the latest Pixel series phones, features an 8-core Cortex CPU, a 20-core Mali-G78 MP20 GPU, and an NPU for accelerated AI models at 5.7 TOPS, with a maximum power consumption of 10W.
GreenWaves launched the GAP9 edge inference chip, boasting ultra-low power at 50mW, peak performance at 50GOPS, and supporting a wide range of precision, including INT8,16,24,32, and FP16,32.
IBM’s NorthPole processor, showcased at HotChips 2023, features 256 cores with near-compute memory storage of 192MB, eliminating the need for off-chip memory during deep learning computations, thus improving latency and energy efficiency. It can compute 800, 400, and 200 TOPS at INT2, 4, and 8 precision, respectively, on a 12nm technology with 220 billion transistors on an 800 sq. mm chip.
Imagination’s PowerVR Series3NX edge processors for IoT to autonomous vehicles achieve up to 160TOPS with the multi-core configuration, designed for ultra-low-power applications.
Intel released several edge AI processors, including the Nirvana Spring Crest NNP-I and Movidius. The latest fourth-generation Xeon processors cater to setups from desktops to ultra-edge devices, offering 9W power consumption at INT8 precision with SuperFin and 10nm technologies, boasting a 40% performance increase and power reduction.
IBM developed the AIU based on its 7nm Telum AI accelerator, scaled down via 5nm technology, featuring a 32-core design with 23 billion transistors.
Leapmind’s Efficiera is tailored for low-power edge AI inference, achieving 6.55 TOPS at 800 MHz clock frequency with an efficiency of 27.7 TOPS/W.
Kneron’s KL720 and KL530 edge inference processors target automotive and smart industrial applications, supporting INT4 and INT8 precision, achieving up to 1.4 TOPS/W.
Memryx’s MX3 inference processor uses BF16 activation functions, computing at 5TFLOPS with 1W power consumption, storing 10 million parameters on-chip for larger network requirements.
Mobileye and STMicroelectronics introduced the EyeQ5 SoC for autonomous driving, offering 24TOPS at 10W and a future EyeQ6 variant promising a fivefold speed boost.
NXP’s i.MX 8M+ edge processor for vision, multimedia, and industrial automation integrates a Cortex-A53 processor with a 2.3TOPS NPU at 2W, anticipating the next-gen i.MX9 AI processor in 2023.
NVIDIA’s Jetson Nano supports concurrent applications with 472GFLOPS at FP16 precision and 5-10W power consumption, with the Jetson Nano B01 achieving 1.88TOPS. The newer Jetson Orin includes the AGX Orin with a 12-core CPU, achieving 275TOPS of performance.
Qualcomm’s QCS8250 SoC for intensive camera and edge applications integrates Hexagon V66Q DSP for machine learning with IoT and 5G support, delivering 15TOPS at INT8 precision.
Qualcomm’s Snapdragon 888+ 5G processor enhances smartphones with AI, gaming, streaming, and photography, featuring a sixth-gen Qualcomm AI engine yielding 32TOPS at 5W. The Snapdragon 8 Gen2 platform achieves 60% better efficiency at INT4 precision.
Samsung’s Exynos 2100 AI edge processor for smartphones, smartwatches, and automotive supports 5G networks, executing AI computations through triple NPUs, showing 26TOPS with 20% reduced power.
SiMa.ai’s MLSoC for computer vision applications, fabricated using TSMC’s 16nm technology, calculates 50TOPS while consuming 10W, using INT8 precision.
Tsinghua University and Ark Lab released the QM930 accelerator, formed by seven chips, utilizing 12nm CMOS technology for INT4, INT8, and INT16 computations, delivering 40, 20, and 10TOPS respectively.
Verisilicon’s VIP 9000 neural network unit for facial and voice recognition employs Vivante’s VIP V8 architecture, supporting INT8, INT16, FP16, and BF16, scalable up to 100TOPS.
Yelp’s EV7x multi-core processor for vision applications integrates vector DSP, vector FPU, and neural network accelerators, peaking at 2.7TOPS.
Tesla’s FSD processor, built by Samsung for autonomous vehicles, features 2 NPUs performing 36.86TOPS each, yielding a peak performance of 73.7TOPS.
Several other companies have also developed edge processors but have not disclosed hardware performance details publicly. Ambarella’s processors for automotive, security, consumer, and IoT applications mainly use ARM processors and GPUs for DNN computations.
Neuromorphic Edge AI Processors
Synsense, formerly AICTx, offers ultra-low-power neuromorphic processors: DYNAP-CNN, XYLO, DYNAP-SE2, and DYNAP-SEL. Performance details for DYNAP-CNN include a 12 sq. mm chip area with asynchronous processing circuitry.
BrainChip’s Akida series of spiking processors features 80 NPUs with 3pJ per synapse operation, operating at 2W. The NPU contains 8 neural processing engines covering convolution, pooling, and activation (ReLu) operations. Future releases include smaller and larger Akida processors under labels AKD500, AKD1500, and AKD2000.
GrAI Matters Lab’s VIP low-power, low-latency AI processor, targets on-device audio/video processing, consuming 5-10W, with tenfold lesser latency than NVIDIA nano.
IBM’s TrueNorth neuromorphic spiking system for real-time tracking, recognition, and detection consists of 4096 synapse cores and a million digital neurons. It consumes 65mW, delivering 46GSOPS/W, with chip area at 430mm^2.
Innatera’s neuromorphic chip using TSMC’s 28nm processes 200fJ per pulse event, targeting audio, healthcare, and radar voice recognition.
Intel’s Loihi, and its updated version Loihi 2, supports evaluating up to 1 million neurons and 120 million synapses, using online learning. These processors use various frameworks for programming, including Nengo and Lava.
IMEC’s neuromorphic processor based on RISC-V architecture implements optimized BF-16 processing pipelines, supporting INT4 and INT8 precision.
Koniku’s hybrid electro-silicon system mimics olfactory receptors, mainly used for security, agriculture, and safe flight operations, with parametric details pending release.
PIM Processors
Imec and GlobalFoundries’ DIANA processor, for DNN processing, includes digital cores for parallel processing and analog memory computing cores for higher efficiency using SRAM arrays. The system is designed for a wide range of edge applications from smart speakers to autonomous vehicles.
Gyrfalcon offers multiple PIM processors, including the Lightspeeur series for CNN computations, achieving high efficiency like the latest Lightspeeur 2803S at 16.8TOPS with 0.7W power consumption.
Mythic’s M1076 analog matrix processor integrates 76 compute blocks, delivering up to 25TOPS, supporting high efficiency for edge devices.
Samsung’s HBM-PIM system successfully integrates AI processing into high bandwidth memory, enhancing supercomputer data processing with increased performance and reduced energy consumption.
Untether’s TsunAImi PIM AI accelerator card for data center inference utilizes runAI200 chips with 192MB SRAM, offering 2008TOPS at 400W.
UPMEM’s PIM system integrates thousands of DPU units within DRAM chips, controlled by main CPU applications, achieving high parallelism for applications such as DNA sequencing and genome comparison.
Edge Processor Performance Analysis
Edge processors are analyzed based on different architectures and key metrics such as performance (TOPS), energy efficiency (TOPS/W), power (W), and area (mm^2). PIM processors typically show better efficiency and lower power consumption compared to data-flow processors, suitable for edge applications needing low power and high performance.
Commercial Processor Pricing and Applications
The cost of commercial processors varies based on performance, efficiency, and application type. Low-performance processors for wearables range from $3 to $10. Mid-range processors for security applications are around $100, whereas high-end processors for autonomous vehicles and industrial applications can range from hundreds to thousands of dollars, like Tesla FSD at $8000 and NVIDIA Jetson Orin around $2000.
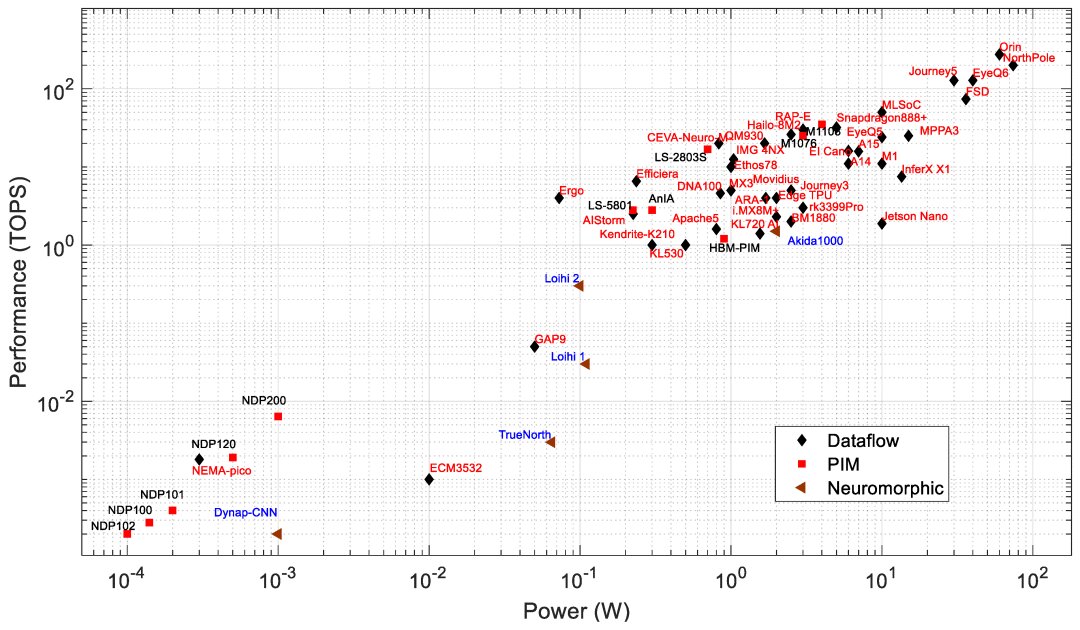
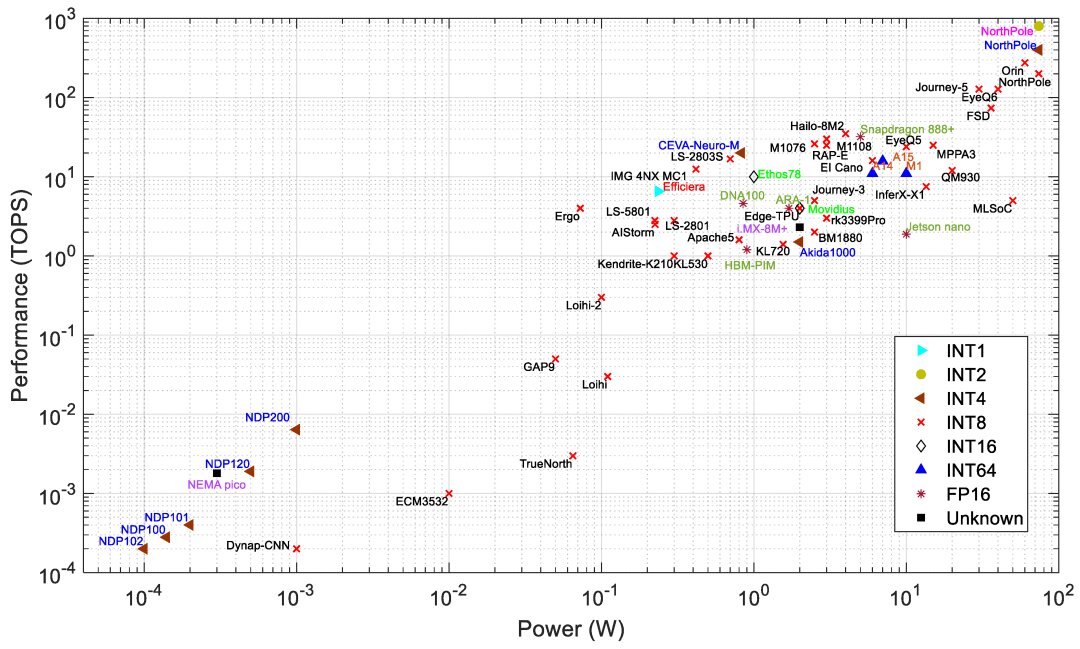
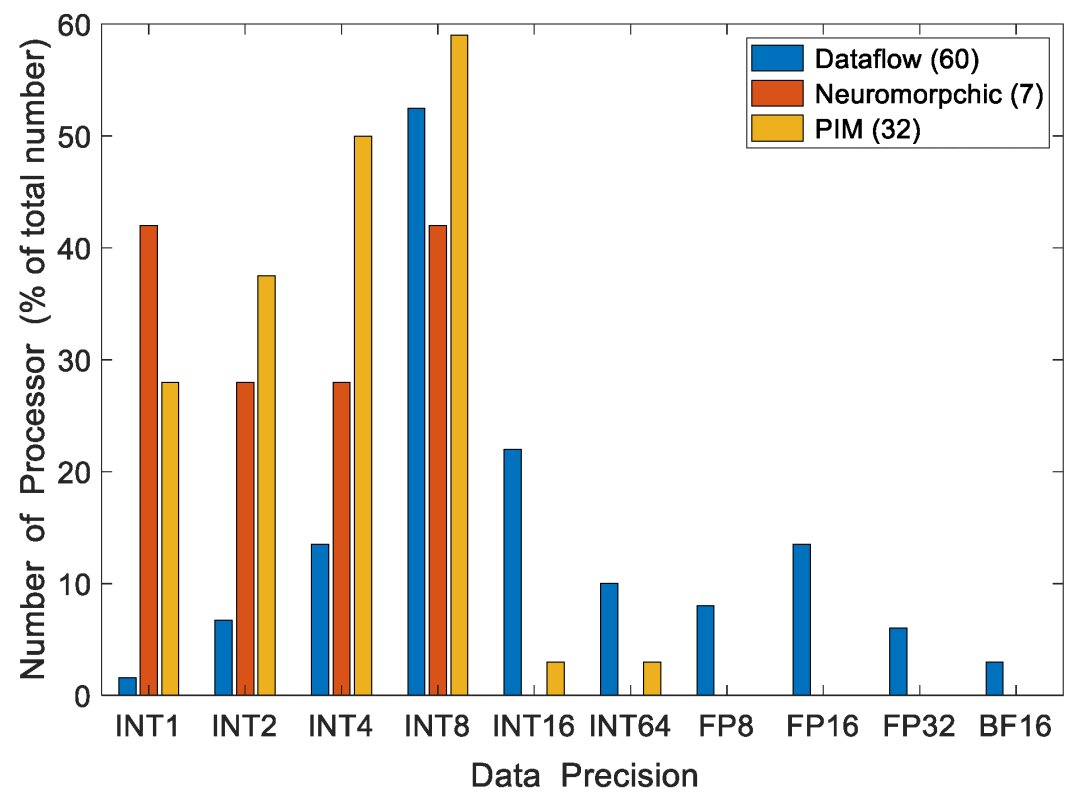
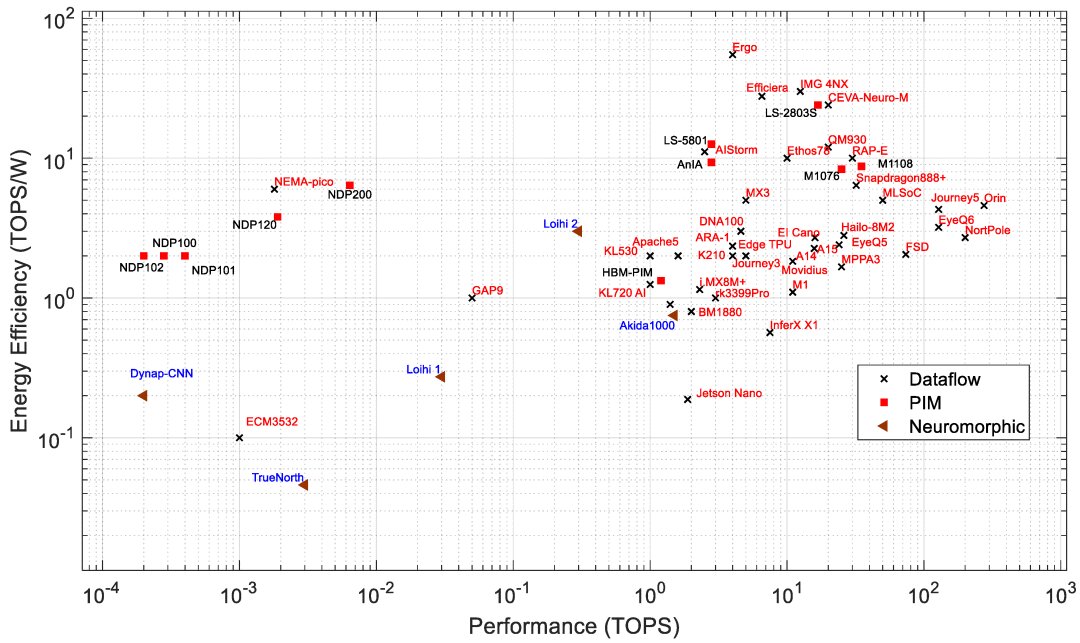
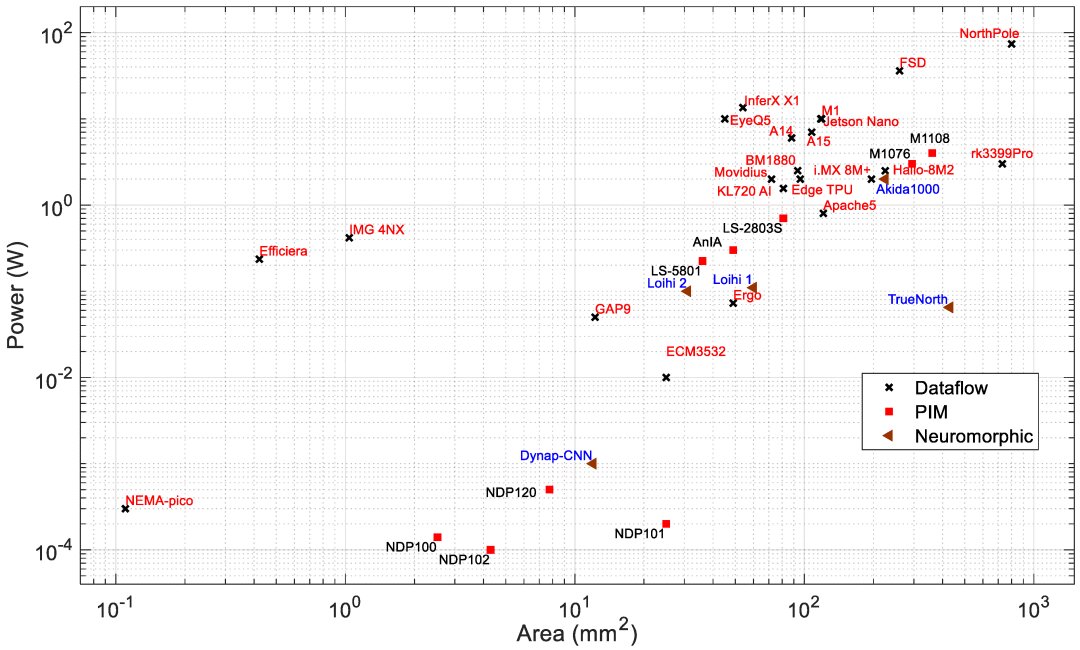
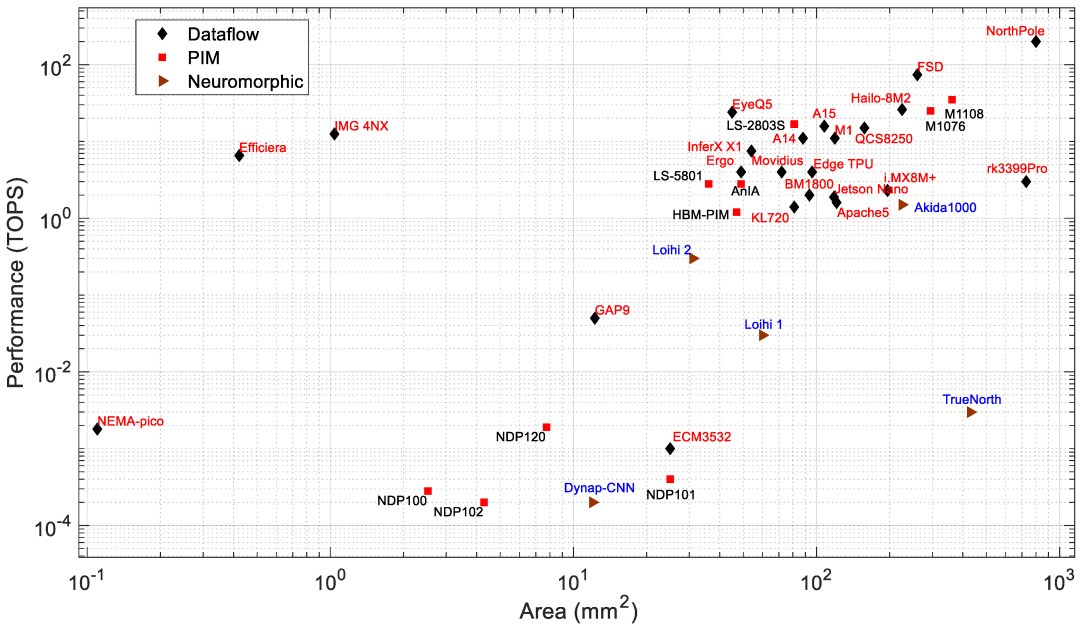
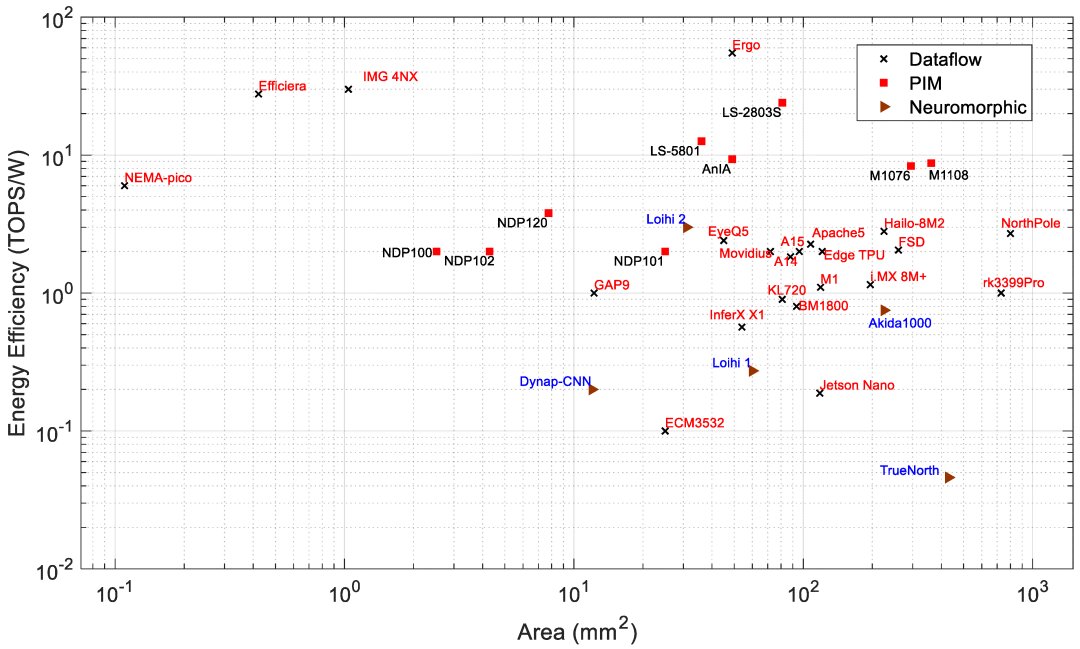
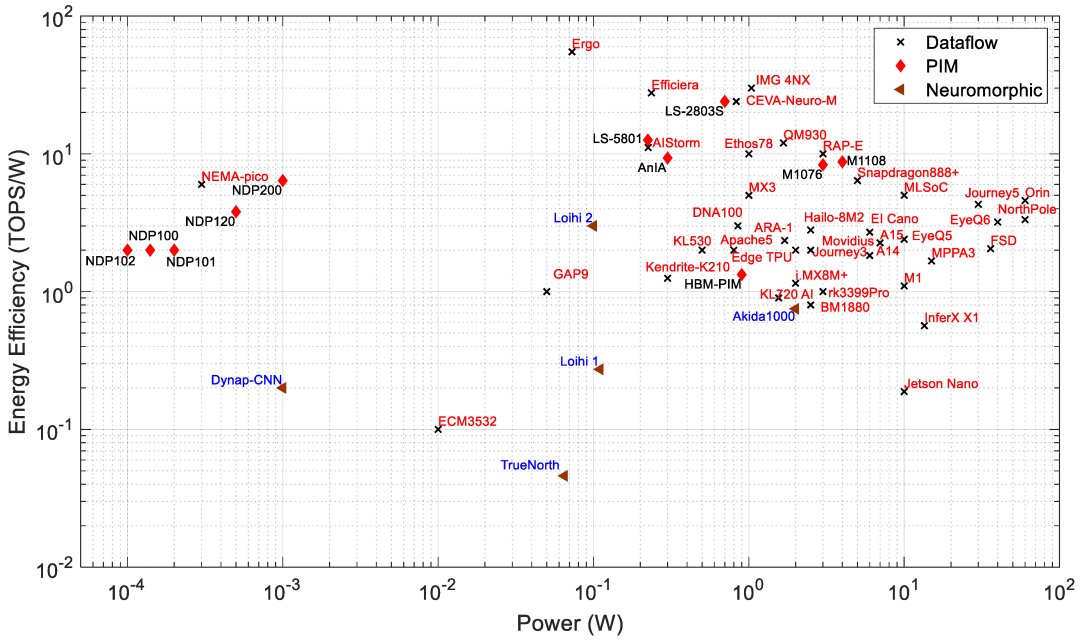
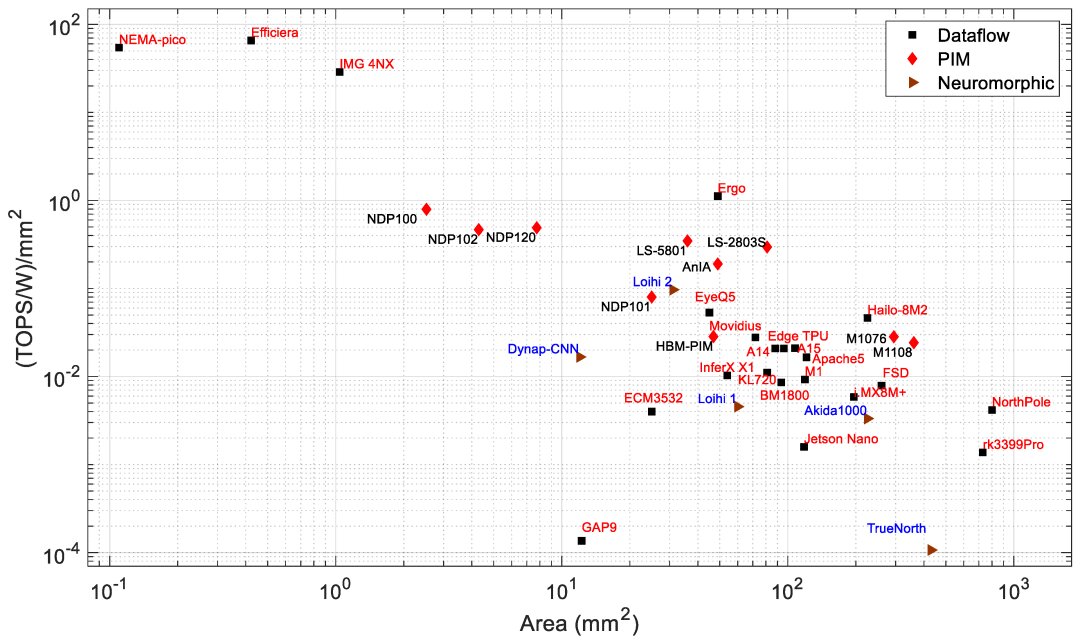
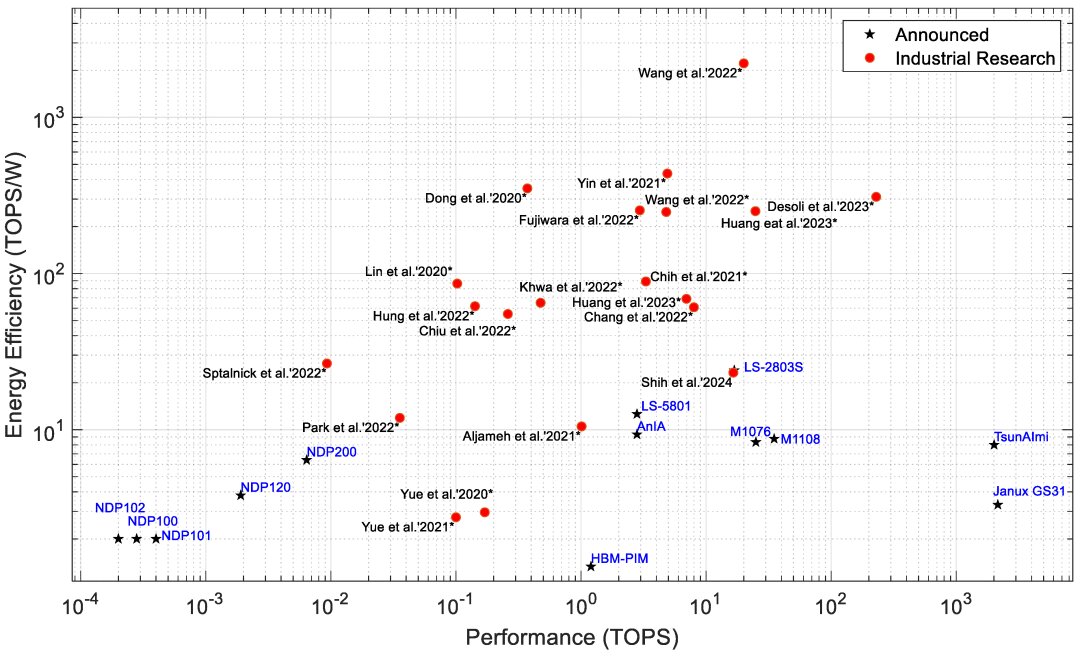
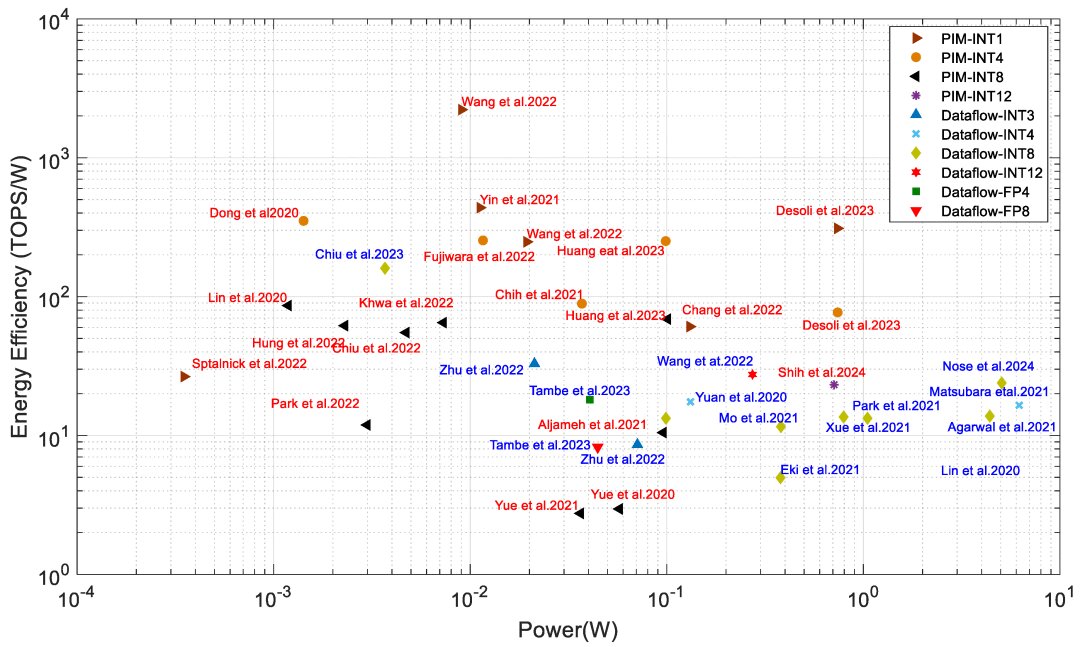
For a detailed table on all AI processors discussed, refer to:
https://www.mdpi.com/2079-9292/13/15/2988